Massive. Huge. Catastrophic. These are all headlines I’ve seen today that basically say we’re now well and truly screwed when it comes to security on the internet. Specifically though, it’s
this:
The Heartbleed bug allows anyone on the Internet to read the memory of the systems protected by the vulnerable versions of the OpenSSL software.
Every now and then in the world of security, something rather serious and broad-reaching happens and we all run around like headless chicken wondering what on earth it means. Did the NSA finally “get us”? Is SSL dead? Is the sky falling? Well it’s
bad, but not for everyone and quite possibly not as bad as many are saying it is. Most of the early news has come via
heartbleed.com(a site created by
Codenomicon) which, if I may say so, has done an excellent job of standing up a very nice little website and branding the bug:
But it’s actually a lot more complex than the shiny logo suggests. It doesn’t help that it’s not an easy concept to grasp and that alone compounds the confusion and speculation about what the bug really is, what the bug is not and perhaps most importantly, what you need to do about it. I’m going to try and distil the issue into a set of common questions people are asking – Heartbleed in a nutshell, if you like.
What’s OpenSSL and what versions are affected?
Let’s start here: the Heartbleed bug is only present in the
OpenSSL implementation of SSL and TLS (note that even whilst not always the same thing, these acronyms tend to be used interchangeably and
usually refer to their implementation over HTTP or in other words, HTTPS). As the name suggestions, this is an open source software product that facilitates communication over the SSL protocol and it is
extremely common. At the time of disclosure, about
17% of the world’s “secure” websites were said to be vulnerable to the bug.
The Heartbleed bug itself was introduced in December 2011, in fact
it appears to have been committed about an hour before New Year’s Eve (read into that what you will). The bug affects OpenSSL version 1.0.1 which was released in March 2012 through to 1.0.1f which hit on Jan 6 of this year. The unfortunate thing about this timing is that
you’re only vulnerable if you’ve been doing “the right thing” and keeping your versions up to date! Then again, for those that believe you need to give new releases a little while to get the bugs out before adopting them, would they really have expected it to take more than two years? Probably not.
Edit: Note that if you're running a beta of OpenSSL, version 1.0.2 is also vulnerable.
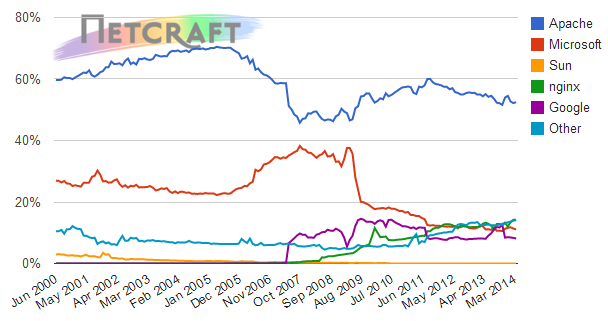
Is it only sites on Apache and nginx that are affected?
Not all web servers are dependent on OpenSSL. IIS, for example, uses
Microsoft’s SChannelimplementation which
is not at risk of this bug. Does that mean that sites on IIS are not vulnerable to Heartbleed? For the most part, yes, but don’t get too cocky because OpenSSL may still be present within the server farm. A case in point: Tim Post from Stack Overflow tweeted this earlier today:
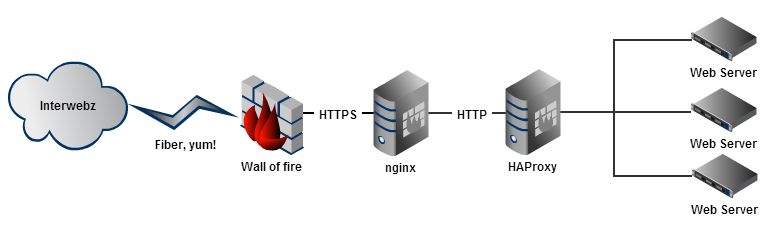
But aren’t they running all ASP.NET MVC on IIS? Yep, they sure are, it’s made very clear in Nick Craver’s excellent post last year on
the road to SSL, in fact you can see the (IIS) web servers all sitting over there to the right in this image:
Wait – is that nginx in there too??? Yeah, about that:
HTTPS traffic goes to nginx on the load balancer machines and terminates there.
You see the problem? Yes, they may be using IIS but no, it doesn’t mean that OpenSSL doesn’t feature in their server farm architecture and indeed it’s sitting out there at the front of everything else terminating the SSL. The same issue exists if a machine acting as a reverse proxy is sitting in front of IIS and running Apache or nginx.
Here’s another one, in fact I received this myself last night from AppHarbor regarding ASP.NET hosting I have with them:
The point is that often server infrastructure is much more than just the web server alone and not consciously running on Apache or nginx doesn’t mean it doesn’t feature in your environment.
Who found it and why make it public?
The first public evidence of the bug appeared as
an OpenSSL advisory on April 7 and warns of “A missing bounds check in the handling of the TLS heartbeat extension”. The bug was discovered and reported by Neel Mehta of Google Security and simply states the impacted versions and recommends upgrading OpenSSL or if that’s not feasible, recompiling it and disabling the heartbeats.
As for why it was made public, this is the age old debate of whether public disclosure fast-tracks remediation or opens vulnerable systems up to attack. Probably a bit of both, the problem with a risk like this as opposed to a single discrete vulnerability on a website is that in order to fix it you need mass uptake of the revised version and until the risk gets socialised, that’s not going to happen. You then have this problem where it only takes one party with malicious intent to start running rampant against sites that are entirely ignorant of the risk and you’ve got a really serious problem.
Regardless, you can’t argue with the focus it’s getting now or the speed with which many are now remediating vulnerable sites. Of course there’ll be others that lag behind and they’ll be the ones at serious risk, let’s take a look at just what that could mean for them.
What’s an SSL heartbeat?
Let’s first understand the feature that this bug has made its way into. The bug we’re talking about here exists in OpenSSL’s implementation of the heartbeat extension, a feature
described by the IETF as follows:
The Heartbeat Extension provides a new protocol for TLS/DTLS allowing the usage of keep-alive functionality without performing a renegotiation and a basis for path MTU (PMTU) discovery for DTLS.
In other words, it’s a heartbeat in the same vein as we commonly know it in other aspects of computer systems, namely it’s a check to see if the other party is still present or if they’ve dropped off. When they’re still there, the heartbeat keeps the context between the peers alive hence the “keep-alive” nomenclature. In the context of SSL, the initial negotiation between the client and the server has a communication overhead that the heartbeat helps avoid repeating by establishing if the peer is still “alive”. Without the heartbeat, the only way to do this is by renegotiation which in relative terms, is costly.
How is the risk exploited? And how was it fixed?
buffer = OPENSSL_malloc(1 + 2 + payload + padding);
As Rahul explains:
In the above code memory is allocated from the payload + padding with a user controlled value. There was no length check for this particular allocation and an attacker could force the Openssl server to read arbitrary memory locations.
In other words, an attacker can control the heartbeat size and structure it to be larger than expected, fire it off to the target server using TCP on port 443 and receive a response that contains up to 64kb data in a memory allocation outside the bounds of what the heartbeat shouldbe able to access. Do it again with a different heartbeat size, get another 64kb response from another memory space. Lather, rinse, repeat. Easy peasy.
You can go and inspect the code and the consequent fix
in this commit on GitHub if you want to get down into the nitty gritty but in short, the payload is now “bound checked” (it can’t exceed 16 bytes) and the entire heartbeat is now validated to ensure it does not exceed the maximum allowable length.
Ultimately this boiled down to a very simple bug in a very small piece of code that required a very small fix. Now it just needs to be installed on half a million vulnerable websites.
What’s the risk? What goes wrong if it’s exploited?
missing bounds check in the handling of the TLS heartbeat extension can be used to reveal up to 64k of memory to a connected client or server
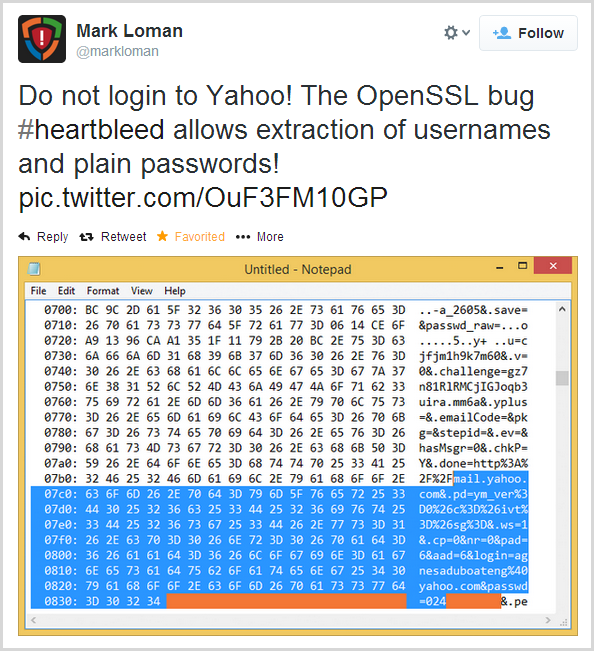
Ok, but what does that actually mean? It means an attacker can do stuff like this:
In case the gravity of this is not clear, what’s being asserted here is that Mark was able to read the credentials of another user (in this case "agnesaduboateng@yahoo.com" and their password which has been obfuscated) directly from memory in Yahoo’s service and he’s done all that remotely just by issuing an SSL heartbeat. Whoa.
More specifically, we’re looking at what was an encrypted HTTPS request to Yahoo’s website (inevitably a POST request to the login page), and we’re seeing a component of that request that was still resident in memory when Mark exercised the exploit and pulled the data. So what else can an attacker gain access to via this bug? Credentials are one thing, but of course this is just by virtue of them occupying memory space which is inevitably but one piece of data in there. Another is the session ID or auth token; even if you can’t pull a user’s credentials via the bug (it’d have to still be in memory at the time), you can still pull the ID that persists their session across requests and consequently enables the attacker to hijack that session and impersonate the user.
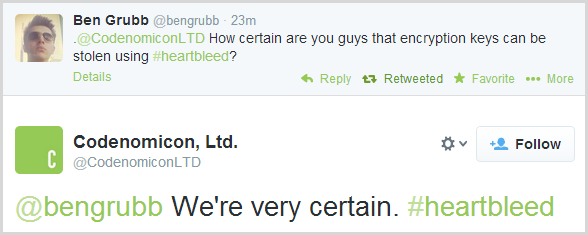
The other
really serious piece of data that could be pulled is the private key of the certificate. I’m going to repeat precisely what
heartbleed.com summarises with regards to leaked primary key material because they summarise it so eloquently:
These are the crown jewels, the encryption keys themselves. Leaked secret keys allows the attacker to decrypt any past and future traffic to the protected services and to impersonate the service at will. Any protection given by the encryption and the signatures in the X.509 certificates can be bypassed. Recovery from this leak requires patching the vulnerability, revocation of the compromised keys and reissuing and redistributing new keys. Even doing all this will still leave any traffic intercepted by the attacker in the past still vulnerable to decryption. All this has to be done by the owners of the services.
Don’t miss the severity of that piece around past interception;
the exposure of the private key presents the opportunity to decrypt data that was previously sent over the wire before this vulnerability was even known. If someone was to have been storing these
pcaps(*cough* NSA *cough*)
and they’ve then been able to pull the keys by exploiting this bug, all your previous data are belong to them.
It can be that bad. In theory – but then there’s this:
Remember Neel? Yeah, he’s the guy that found the bug to begin with. Is he right and everyone else is wrong? Maybe. Maybe not:
What about Codenomicon – remember them too? They’re the guys who created the
heartbleed.com website I keep referring to which has become such a canonical reference for the bug.
Regardless of whether keys are or are not remotely accessible, there’s still all that other addressable memory that leads to exposed credentials and session IDs. Then there’s all the other data in the HTTPS comms that you
really don’t want being remotely and anonymously accessible, it’s just a question of whether the bug also compromises the certificates themselves and there are enough
whispers of people having been able to do that to plan for the worst and hope for the best.
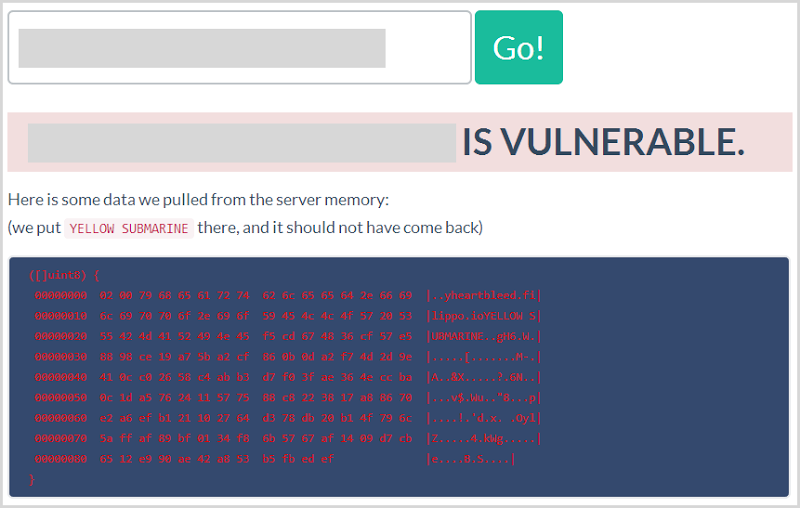
How do you tell if a site is vulnerable?
Ok, so what are we looking at here? Filippo has kindly
open sourced the code on GitHub so we can take a peek inside. In short, he’s simply committing the string “YELLOW SUBMARINE” to the padding of the heartbeat (go back to the earlier piece by Rahul Sasi for context), sending the heartbeat off then watching to see if it appears in the response. There’s a bit more to it than that, but you get the idea.
Why did it take 2 years to find the risk – isn’t open source “secure”?!
The theory goes like this – “Open source software is more secure because the community can inspect it and identify bugs much earlier”. The key word in that statement, of course, is can, notwill.
The
OpenSSL project on GitHub has over 10,000 commits spanning 21 contributors and 25 branches across 57MB of source code. It’s not huge, but there’s enough in there and the bug is obscure enough
in retrospect that it went unnoticed until now. We think – perhaps others noticed earlier on and exploited it. Speaking of which…
Is the NSA / GCHQ / Russian Mafia in on it?
Yes. Next question?
Seriously though, we’ve now got an insight into the extent that governments will go to in order to intercept and decrypt private communications en masse and without targeting (and don’t for a moment think it’s just the US doing this – have we forgotten China et al already?!), can you imagine how attractive this would be to organisations that have been performing mass packet captures? If indeed it is possible to pull private keys remotely from servers, this would be an absolute goldmine and it’s a hell of a lot easier than some of the things we now know the governments have been up to.
Governments are one things, what about career criminals? One of the worrying things about this risk is the ease with which it can be automated. We’re already seeing this happen both for good (mass testing of an organisation’s web assets) and bad (mass testing of another organisation’s web assets). That it can be done remotely, expeditiously and by enumerating through multiple hosts makes it all the more attractive and I’ll be massively surprised if criminals haven’t already weaponised this into a mass data exfiltration tool.
Will reissuing certs fix the problem?
Yes and no. Firstly, there’s no point in doing this until you first patch the servers OpenSSL is running on otherwise you’re simply putting a brand new cert at risk.
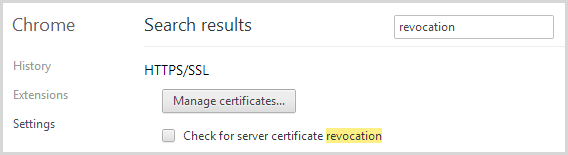
Moving on, if you work on the assumption that private keys on vulnerable sites have been compromised (and that’s the safest assumption if you’re being cautious), then yes, certificates should be reissued and the old ones revoked. But here’s the problem with revocation – check out Chrome’s default setting:
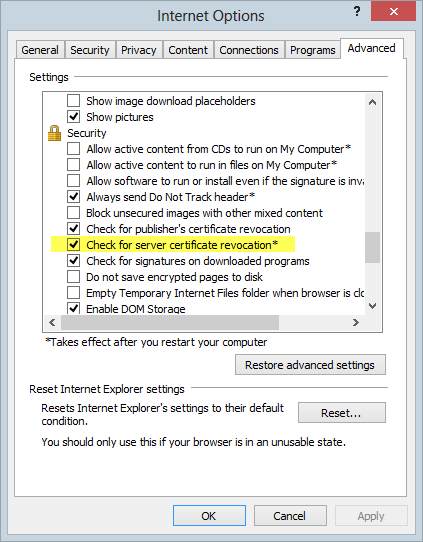
Yeah, no default check for revoked certs in Chrome. How about Internet Explorer:
Yes, that’s the default setting and it has been since IE 7. But of course Chrome now has the lion’s share of the browsing audience so whilst reissuing the cert and revoking the old one is a good move where vulnerable versions of OpenSSL have been present, that’s not necessarily going to stop clients from trusting revoked certs. Nasty.
But beyond just the technical logistics of how revoked certs are validated (or not), there’s also the cost impact. Usually, certs cost money. Sometimes cert
revocation costs money. As friend and all round smart security guy
Casey Ellis said this morning, there are a whole bunch of cert vendors sitting around doing this right now:
There’s rarely a serious security incident without big opportunities being presented to players in the security industry.
How do you tell if you’ve already been compromised?
Yeah, about that –
you can’t simply trawl back through the usual logs on find traces of a compromise. Again from
heartbleed.com:
Exploitation of this bug leaves no traces of anything abnormal happening to the logs.
The problem is that this bug isn’t exploited via channels that would typically be logged. If, for example, you get pwned by a SQL injection vulnerability then your web server logs are full of dodgy HTTP requests. Of course this then raises a very uncomfortable question: if your site was vulnerable, do you work on the assumption that you’ve been compromised?
There’s a whole range of things that need to fall into place for an attack to have been successful (see the final section of this blog) but nonetheless, it’s going to leave a lot of companies in a verytricky position when they know that both the potential for exploit and the knowledge of how to do it were both out there. Take Yahoo for example – what should they do in light of Mark’s documented example? Force everyone to reset their passwords? Tell customers their data mayhave been compromised? It’s a very, very dicey situation for them to find themselves in.
Can attacks be identified by intrusion detection / protection systems?
Bro can detect this attack
in several different ways. In the simplest incarnation, which is the only one we have seen in the wild so far, the heartbeat message is sent very early, before the TLS encryption kicks in.
In these cases, Bro just compares the payload and message sizes. If there is a mismatch, we know that an exploit has been tried. If the server responds to the message it very probably was vulnerable to the attack.
Of course there’s also the risk that an overzealous IPS (Intrusion Protection System such as
Snort) may block heartbeat requests altogether (a risk
heartbleed.com refers to), but frankly, if the site is indeed vulnerable to the risk then that’s not a bad position to be in and it’s the same end result as recompiling OpenSSL with heartbeats disabled. Yes, it may do unpleasant things to your perf for a little bit, but the possible alternative is much, much worse.
If you’re running an IPS and you’ve not been able to patch the underlying risk then it’s worthwhile taking just a little look at whether signatures may be available to mitigate the problem in the interim.
What’s impacted beyond just HTTPS?
Anything that has an OpenSSL dependency which could include VPN implementations, instant messaging clients, email and a bunch of other things I almost certainly haven’t thought of. Just because you’re not seeing HTTPS in the address bar doesn’t mean you don’t have a risk.
Does perfect forward secrecy fix all this?
Yes, but not retrospectively and only the potential risk of exposed keys, not the scenario where memory contents are exposed. The idea of
perfect forward secrecy is that the exposure of one key shouldn’t bring the whole house of cards crashing down:
Public-key systems which generate random public keys per session for the purposes of key agreement which are not based on any sort of deterministic algorithm demonstrate a property referred to asperfect forward secrecy. This means that the compromise of one message cannot lead to the compromise of others, and also that there is not a single secret value which can lead to the compromise of multiple messages.
In the context of Heartbleed, if the private key can be pulled from memory it wouldn’t lead to the compromise of every single message as they’d be uniquely keyed. But again, this is something that you put in place now for the future, it’s not a solution to Heartbleed, it’s too late for that.
I’m a sys admin – what do I do?
If you’re responsible for maintaining the infrastructure and web server on which sites run, there’s a one clear immediate step: update your OpenSSL to version 1.0.1g as a matter of priority. If that’s not feasible, you can recompile OpenSSL and have it disable the heartbeat with this switch:
-DOPENSSL_NO_HEARTBEATS
As I explained earlier though, heartbeats serve a purpose and turning them off may have a perf impact so treat that as stop gap only.
The next steps depend on your risk aversion or paranoia level depending on how you look at it. That and the value of the information you’re protecting. Those steps may also be the domain of the developer and could include:
- Reissuing any impacted certificates
- Revoking any impacted certificates
- Looking at the availability of blocking malicious heartbeat requests at the IPS level
- Expiring any active user sessions
- Forcing password resets on any user accounts
This is the advice I’ve received from AppHarbor with regards to my websites hosted with them (although I’ve added the point on the IPS) and whilst you could argue that this is erring on the safe side, you could also argue that’s precisely what we should be doing just now.
I’m a developer – what do I do?
First of all, make sure you’ve read the previous section for sys admins. Many developers find themselves doing all sorts of stuff that’s theoretically the domain of server people who get their hands dirty making all the infrastructure work for the rest of us.
The frustrating part for me as someone who tries very hard to bridge the gap between development and security disciplines is that this bug means I can no longer simply say “Developers, focus on implementing SSL in your web apps and don’t worry about the underlying protocol”. Of course you still want to make sure that SSL is configured appropriately to begin with (have a go of the
Qualsys SSL Labs test for a free check), but it’s no longer just a matter of getting that right from the outset then proceeding to focus solely on marking cookies as secure and not loading login pages over HTTP and so on and so forth.
One extremely pragmatic piece of advice I can give is simply this: don’t collect or store what you don’t need. I recently had to deal with an incident involving the collection of registrants’ religion, a piece of very sensitive data to many people and this was in a foreign country that’s not always particularly tolerant if your world view doesn’t line up with theirs. Why did they need it? They didn’t, it just “seemed like a good idea at the time”. You can’t lose what you don’t have and that approach will protect data not just from exposure via Heartbleed, but from SQL injection attacks and insecure direct object references and session hijacking and a whole bunch of other nasties that have the potential to exploit customer data.
I run an online service – what do I do?
The thing to consider now is what damage could be done by an attacker if they’ve been able to obtain user credentials, sensitive data or hijack sessions. What could an attacker access if they were logged in as a user? What could they authorise? What could they then do with that information?
One of the biggest problems here is that you’re almost certainly not going to be able to tell if you’ve been compromised. You can tell if you were at risk and know that you’ve been left vulnerable, but you can only speculate about the window of vulnerability. You don’t know when an attacker first became aware of that risk – it was only socialised in the last couple of days, but it was introduced more than two years ago. Even if it only took you hours to patch, was enough time to be exploited?
The most cautious approach in the security sense is to force password resets and explain to customers that there may have been “an incident”. That’s not a pleasant experience for you nor for your customers and there's a trade-off to be considered between what makes sense security wise and what the impact on trust and the general user experience might be. It’ll be a case-by-case decision and it won’t be easy.
What do I tell my non-technical friends to do?
Break out the tinfoil hats? Turn off all their things? Take a break on a desert island until things calm down? This is one of those things where consumers won’t be the ones that need to take direction action in relation to the bug, at least not in the same way as, say,
the goto bug in iOS recently which resulted in an update to the OS. They’re not the ones patching bad OpenSSL on web servers (although we’re yet to see if this risk may impact
clients with OpenSSL dependencies).
On the other hand, they may need to take action if the bug has resulted in the exposure of their credentials or other personal data. Ideally this will be advice given to them by websites that have reason to believe there may have been a compromise, that is if they’re proactive enough to identify the risk and (arguably) responsible enough to advise their customers to take preventative action. It’s also an activity that should only be performed after a vulnerable site is patched and a new certificate installed – it’s no good going and putting a shiny new password into a site that may still expose it to an attacker.
Of course it also serves as another valuable reminder to consumers –
The only secure password is the one you can’t remember. This is an oldie but a goodie and the premise remains the same; we must
always make the assumption that passwords will eventually be compromised and that they must be both strong and unique which means that committing them to memory –
human memory– is out. Two factor is another biggie and you want to make sure this is turned on at every possible location (Dropbox, GitHub, Evernote, Microsoft Live ID, etc). This won’t all solve the problems of Heartbleed, but it’s about the extent to which consumers can influence it.
But is it really that bad? And what happens next?
Multiple things have to line up in order for this bug to lead to successful exploitation:
- The site has to implement SSL in the first place – no SSL means no OpenSSL means no Heartbleed bug.
- The site has to be running OpenSSL. That rules out a significant chunk of the internet, including most IIS websites.
- The OpenSSL version has to be somewhere between 1.0.1 and 1.0.1f; anything older or newer and the bug isn’t present.
- An attacker needs to have had access to an at-risk environment somewhere between learning of the bug and it being patched by the provider.
- If all these things line up, there must have been something useful and retrievable from memory at the time of the attack. That’s highly likely in all but the most dormant sites.
- But regardless of current site activity, if the attacker had previous pcaps of traffic (hello again, NSA!) and could then pull the private key from the site, that’s a serious problem.
The problem, of course, is that whilst points 1 through 3 are clearly definable, in most cases we’ll have no idea of whether points 4 and on actually happened. How long did an attacker know about the risk before it was patched? Were they then able to gain access to the server? Was there anything useful in memory at the time? Or could they use exfiltrated keys against prior data captures?
It’s very early days right now and a number of different things could happen next. One likelihood is that we’ll see impacted sites requesting password resets; Mark showed how Yahoo is vulnerable, surely they can’t
not now ask people to reset their passwords? I don’t mean to call out Mark specifically either, a quick
trawl through pastebin shows extensive public documentation of vulnerable sites. Or how about all those on
the list of the Alexa Top 10,000 that have all been tested and many shown to be vulnerable? That’s a very big list and in fact the password resets are already happening, I received this one today from AppHarbor:
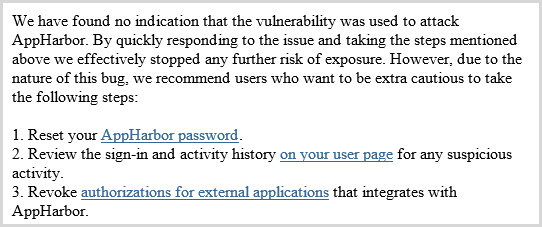
Of course the other risk is that we’ll see exploitation of credentials that have been pulled from vulnerable sites. This could take on many forms; we’ve seen
Acai Berry spam on Twitter after the Gawker breach and many
significantly more serious events as a result of stolen credentials. The problem now is that every time an account is compromised by stolen credentials the question is going to be asked: “Were these popped from a vulnerable site via Heartbleed”? This bug could have a very, very long tail.